MHC-L · PRIVACY
Questa pagina racconta cosa MHC-L fa con i tuoi dati e — altrettanto importante — cosa non fa. Se sei un professionista che sta valutando MHC-L per il proprio studio, o un consulente per la protezione dei dati che lo sta esaminando, è il punto giusto da cui partire. La versione qui descritta è MHC-L 5.5.0.
Lo scopo di questo documento è essere onesto e leggibile in pochi minuti. Niente marketing. Dove la protezione è stretta, lo diciamo.
MHC-L è composto da un piccolo server, ospitato in Europa — a Vienna — e da un’installazione cliente sulla tua macchina. Lo usano professionisti — avvocati, consulenti — che lavorano con Claude (l’assistente AI di Anthropic) su materie che possono includere documenti riconducibili al cliente. Il server espone un piccolo insieme di strumenti per gestire la sessione e formattare gli artefatti che ne derivano. La pseudonimizzazione, quando scegli di usarla, gira interamente sulla tua macchina.
MHC-L non cifra i tuoi file, non mette in sicurezza il tuo computer, non sostituisce la tua infrastruttura informatica, non decide al posto tuo cosa è riservato e non fornisce consulenza legale. È uno strato dentro la tua complessiva disciplina di trattamento dei dati professionali.
MHC-L ti dà un’infrastruttura di sessione e di formattazione degli artefatti ospitata in Europa, più una pipeline opzionale di pseudonimizzazione lato cliente che governi tu — così che il contenuto che scegli di proteggere possa essere reso pseudonimo sulla tua macchina prima di raggiungere Claude.
Tutto il resto di questa pagina chiarisce cosa significa e cosa esclude.
Il server di MHC-L a Vienna è un singolo processo che espone un solo punto di accesso. Quel punto dichiara quattro strumenti — quattro funzioni che il cliente sulla tua macchina può chiamare:
SID-AAAAMMGG-HHMMSS), aggiorna lo storico di sessione dentro la configurazione e restituisce il risultato al cliente, che lo riscrive sul tuo disco.Il server non esegue Claude. Quando chiedi a Claude di lavorare su un atto — revisione di un contratto, triage di un NDA, preparazione di una riunione, controllo di compliance — il prompt e il documento allegato viaggiano dalla tua macchina ad Anthropic, non al server di MHC-L. Il server non ha alcun ruolo nel ragionamento del modello.
Una nota terminologica: il protocollo che il cliente usa per parlare al server di MHC-L si chiama MCP (Model Context Protocol). È una convenzione tecnica per descrivere i quattro strumenti sopra in un formato che Claude può chiamare. Non riguarda la sostanza dei tuoi dati.
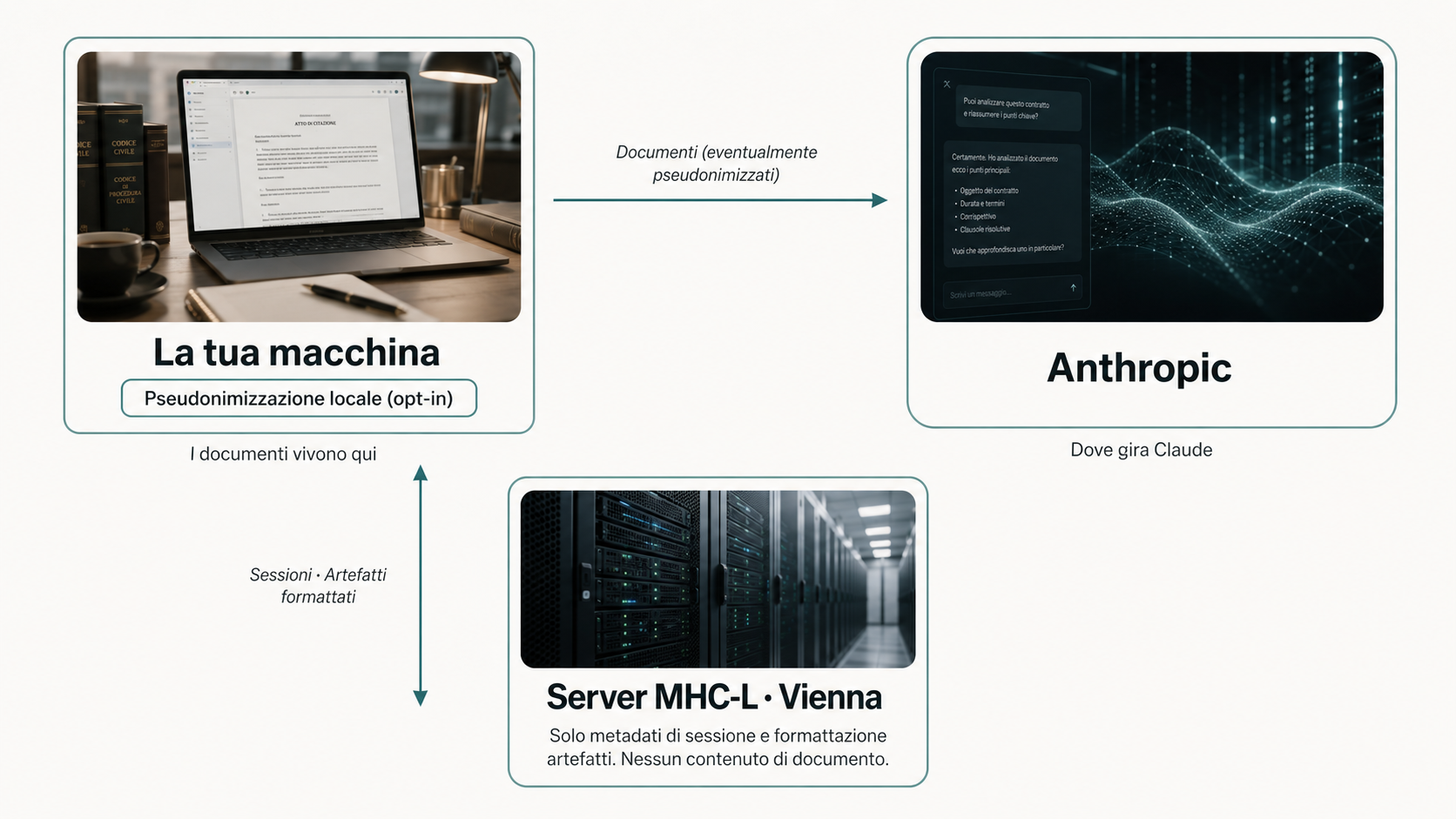
Tre luoghi possono vedere i tuoi dati: la tua macchina, Anthropic (dove gira Claude) e il server di MHC-L a Vienna. Cosa va dove dipende dal tipo di dato.
Viaggiano dalla tua macchina ad Anthropic quando chiedi a Claude di lavorarci. Non raggiungono il server di MHC-L: il server non ha alcun endpoint che riceve documenti utente. Se hai attivato la routine di pseudonimizzazione (vedi sotto), la versione che arriva ad Anthropic è quella pseudonimizzata; se non l’hai attivata, è il documento in chiaro. In entrambi i casi, il server di MHC-L non sta su questo percorso.
Sono brevi testi narrativi — descrizioni del lavoro fatto in una sessione — che decidi di formalizzare come artefatti. Il loro contenuto viene inviato dalla tua macchina al server di MHC-L attraverso lo strumento di creazione artefatto, perché il server possa formattarlo dentro un template markdown e restituirti il file pronto. Il cliente lo scrive sul tuo disco.
Il server riceve quel contenuto in memoria per il tempo della formattazione — è inevitabile, perché sostituire i campi richiede leggerli. Il server non lo registra né lo persiste: niente log, niente scrittura su disco, nessun database. Una volta restituito il markdown formattato, il contenuto è uscito dal lato server.
Quando esegui la routine di pseudonimizzazione su un documento, la routine costruisce una mappa tra i nomi reali che ha rilevato e i nomi finti che ha sostituito (“Tizio”, “Caia”, “Sempronio”, o equivalenti della tradizione italiana). Questa mappa esiste solo in memoria, sulla tua macchina, durante l’esecuzione. Non viene scritta su disco, non viaggia in rete, non raggiunge mai il server di MHC-L, non raggiunge mai Anthropic. Quando la routine termina, la mappa sparisce.
La ricodifica — il passaggio inverso, dagli pseudonimi nell’output di Claude ai nomi reali — ricostruisce la mappa fresca, sempre in memoria, confrontando l’output con il documento originale. Stessa proprietà: solo in memoria, mai persistita, mai trasmessa.
MHC-L include una skill (/mhc-verifica-riferimenti) che verifica le citazioni legali contro fonti esterne — banche dati delle corti, repertori normativi ufficiali, registri pubblici. Quando chiedi a Claude di verificare una citazione, il flusso è diverso da quello della revisione documenti:
Per coperture più ampie — alcune ricerche su Cassazione, alcuni registri di autorità specializzate che richiedono accesso via browser — è disponibile un plugin Chrome opzionale di Anthropic che può essere installato accanto a MHC-L. Il plugin permette a Claude di raggiungere pagine che il percorso di verifica predefinito non copre. Il plugin non è parte dell’installer di MHC-L: lo installi e gestisci tu, e il flusso di dati che vi transita è governato dai termini del plugin di Anthropic, non dal DPA di MHC-L. La sua disponibilità viene segnalata nel banner di installazione e nella mail di onboarding, così che tu possa richiederlo esplicitamente quando lo vuoi.
In questa fase il codice sorgente di MHC-L non è pubblicato su un repository pubblico. È rivedibile dal tuo DPO o dai tuoi consulenti su richiesta scrivendo a mhcl@micheleloi.pro. La pubblicazione su un repository pubblico è una decisione rinviata a una fase successiva, condizionata alla maturità del prodotto, non al tempo.
MHC-L ha una configurazione privacy con due stati possibili. Lo stato è determinato da un’opzione che imposti in fase di onboarding. Il valore predefinito è disattivato.
I due stati differiscono nel grado di protezione del flusso verso Anthropic e verso il server di MHC-L. Entrambi sono legittimi e corrispondono a contesti professionali diversi. Non sono simmetrici: lo stato 1 offre una protezione materialmente più forte dello stato 2.
Hai attivato esplicitamente la routine durante l’onboarding (/mhc-onboard con anonymize=Y). La routine è strutturata in due passaggi opt-in con la tua decisione in mezzo, pensata perché il primo passaggio copra la protezione fondamentale (nomi di persona e identificativi) e il secondo estenda la copertura su tua richiesta:
Un controllo supplementare — il gate locale sui metadati degli artefatti in uscita — gira su quanto sta per essere inviato al server. Cattura casi limite, come un nome digitato direttamente in chat invece di essere incollato dal file pulito, o un nome che Claude ha parafrasato da contesto precedente non pulito. È una rete di sicurezza sopra un flusso di lavoro già protetto, non la protezione primaria. La protezione primaria è la tua revisione al passaggio 6.
Non hai attivato la routine. I documenti vanno in chiaro a Claude. Gli artefatti di sessione che raggiungono il server di MHC-L attraverso lo strumento di creazione artefatto possono contenere nomi reali, riferimenti a fascicoli o altro materiale identificativo se tu o Claude li avete scritti direttamente nella conversazione.
Questo flusso è coperto da:
Lo stato 2 è una configurazione che scegli esplicitamente. È la scelta giusta per alcuni flussi di lavoro e quella sbagliata per altri; questa pagina non decide al posto tuo. Quello che ti dice è: nello stato 2, la protezione poggia sul DPA e sulle garanzie infrastrutturali, non sulla pseudonimizzazione. Non c’è una redazione automatica.
Il default disattivato è una scelta architetturale deliberata, non una svista. Se la routine fosse attiva di default senza un’adesione consapevole alla pipeline completa, MHC-L creerebbe una falsa sensazione di sicurezza: l’utente penserebbe che “il sistema gestisce la privacy” e salterebbe la GUI sui documenti. I documenti in chiaro raggiungerebbero comunque Anthropic — perché il gate locale opera solo sul percorso fra il cliente e il server di MHC-L, non sul percorso fra il cliente e Anthropic. Il server di MHC-L riceverebbe pseudonimi mentre Anthropic avrebbe già visto i nomi reali. La protezione sarebbe asimmetrica e nasconderebbe il vero punto di esposizione.
Mettere il default disattivato costringe chi vuole protezione reale a percorrere consapevolmente l’onboarding e a installare il gate. Quell’attivazione è un’adesione alla routine completa, non un suo sostituto. L’attrito al primo setup è il prezzo deliberato dell’integrità architetturale.
Vale la pena nominare con parole comuni come è disegnata la difesa, perché la geometria — più della singola misura — è ciò che la rende leggibile.
La prima e principale protezione viene dalla disciplina dell’avvocato che, dopo aver eseguito i passaggi della routine, rivede la bozza pseudonimizzata prima di mostrarla a Claude. La routine prepara, suggerisce, sostituisce; ma è la revisione umana — di chi conosce il caso — che chiude le maglie. Nessun riconoscitore automatico cattura tutto, e chi promette il contrario mente per omissione.
Sopra questa protezione primaria gira una rete di sicurezza — il gate locale — che intercetta errori residuali nel percorso verso il server di MHC-L: un nome digitato direttamente in chat invece che preso dal documento pulito, una parafrasi di Claude che recupera un nome da contesto precedente. La rete di sicurezza è utile, ma è supplementare. Non sostituisce la revisione manuale e non va trattata come se lo fosse.
Il server di MHC-L a Vienna non riceve i contenuti dei documenti del cliente. Riceve solo metadati di sessione e i campi narrativi degli artefatti che decidi di formalizzare, in memoria, per il tempo della formattazione. Non li scrive su disco, non li indicizza, non li tiene. È infrastruttura, non un repository.
Resta esplicitamente fuori dall’ambito di MHC-L tutto ciò che riguarda la macchina dell’avvocato (sistema operativo, antivirus, cifratura del disco, accesso fisico, backup) e tutto ciò che riguarda il rapporto fra l’avvocato e Anthropic per il servizio Claude. Quel rapporto è governato dall’accordo che l’avvocato ha già con Anthropic, parallelo e separato dal DPA con MHC-L. Documentazione tecnica completa disponibile su richiesta — scrivi a mhcl@micheleloi.pro.
/mhc-connectors propone due schemi (uno per proteggere ciò che entra, uno per pseudonimizzare ciò che esce) che ti aiutano a tenere il contenuto sensibile fuori da quei flussi./mhc-connectors.MHC-L è attualmente in fase di prova con un piccolo gruppo di tester invitati personalmente. La distribuzione è limitata e gratuita per la durata di questa fase. Non è ancora un prodotto maturo né distribuito al pubblico generale; le scelte architetturali descritte sopra sono ratificate, ma alcune funzioni perimetrali (la pubblicazione del codice sorgente su repository pubblico, alcuni elementi della catena di sicurezza del piano di gestione) sono volutamente rinviate a fasi successive.
mhcl@micheleloi.pro per riceverli o per concordare una revisione.
Per domande puntuali — anche brevemente, anche al telefono o via Signal — il contatto è lo stesso: mhcl@micheleloi.pro.
MHC-L è un prodotto di RegIA — un progetto di Michele Loi, ricercatore in etica e governance AI.